Understanding Distributed Learning: Maximizing Machine Learning
Written on
Chapter 1: Introduction to Distributed Learning
Distributed learning is a pivotal element in the machine learning (ML) framework utilized by contemporary technology firms. By harnessing the power of numerous machines, organizations can train larger models with extensive datasets at accelerated rates, ultimately leading to higher-quality models and swifter iteration cycles.
As Twitter articulates:
"Implementing customized distributed training allows for quicker iterations and the ability to train models on more current data."
Similarly, Google states:
"Our findings indicate that our advanced training techniques can significantly expedite the training of even moderately sized deep networks using a machine cluster, surpassing the speed of a GPU while avoiding its model size limitations."
Netflix adds:
"We aimed to create a vast Neural Network training system that capitalized on both GPU advantages and the AWS cloud, utilizing a manageable number of machines to deliver an effective machine learning solution via a Neural Network framework."
In this article, we will delve into the core design aspects of distributed learning, particularly concerning deep neural networks. Key topics include:
- Model-parallel vs data-parallel training
- Synchronous vs asynchronous training
- Centralized vs decentralized training
- Large-batch training
Let’s dive in.
Section 1.1: Model-Parallelism vs Data-Parallelism
Two primary approaches exist in the distributed training of deep neural networks: model-parallelism and data-parallelism.
Model-parallelism involves distributing the model itself among machines; each machine holds a portion of the model, such as specific layers of a deep neural network (known as 'vertical' partitioning) or particular neurons within a layer ('horizontal' partitioning). This method is beneficial when a model exceeds the capacity of a single machine, yet it necessitates the transfer of large tensors between machines, leading to significant communication overhead. In the worst-case scenario, one machine may remain idle, waiting for another to finish its computations.
Conversely, data-parallelism entails each machine maintaining a complete copy of the model while processing its local data batches through forward and backward passes. This paradigm inherently scales better, as adding more machines to the cluster allows for either a fixed global batch size with reduced local batch sizes or a fixed local batch size with an increased global batch size.
In practice, model and data parallelism can coexist, offering complementary benefits. A hybrid strategy may yield additional advantages, as highlighted in a Twitter blog post.
Lastly, hyperparameter-parallelism allows each machine to run identical models with varying hyperparameters, epitomizing a straightforward parallel approach.
Section 1.2: Synchronous vs Asynchronous Training
Within data-parallelism, a global batch of data is uniformly distributed across all machines at each training cycle iteration. For instance, with a global batch size of 1024 across 32 machines, each machine receives a local batch of 32.
For this mechanism to function, a parameter server—dedicated to storing and managing the most recent model parameters—is essential. Workers relay their locally computed gradients to the parameter server, which subsequently sends the updated model parameters back to them. This can occur either synchronously or asynchronously.
In synchronous training, the parameter server waits for all gradients from every worker before updating the model parameters based on the average gradient. This method produces higher-quality parameter updates, facilitating faster model convergence. However, if some workers take longer to compute their gradients, others must remain idle, which wastes computational resources.
Conversely, in asynchronous training, the parameter server updates model parameters upon receiving a single gradient from any worker, immediately returning the updated parameters to that worker. While this approach eliminates idleness, it introduces the challenge of staleness, as workers may operate with outdated model parameters. The more workers involved, the more pronounced this issue becomes; for example, with 1000 workers, the slowest worker could be 999 steps behind when it completes its computation.
The first video, "Primer Video - History of Distance Learning," provides an overview of the evolution and significance of distance learning in education.
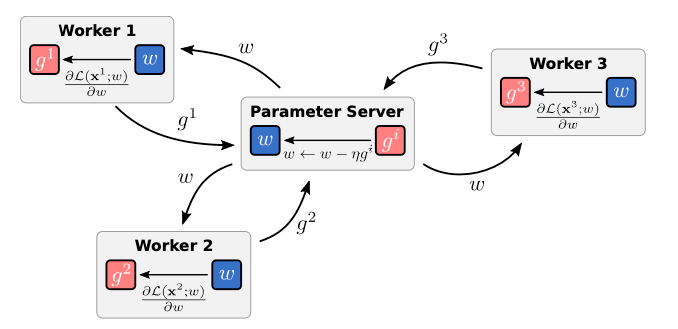
Asynchronous data-parallelism illustrated. Each worker sends local gradients to the parameter server and receives updated model parameters.
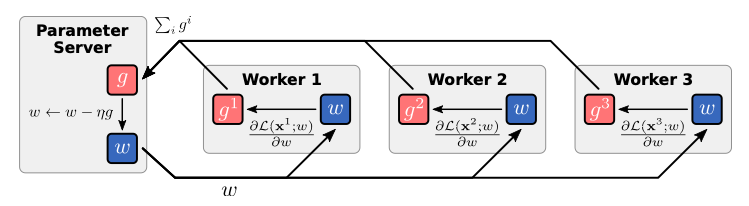
Synchronous data-parallelism depicted. The parameter server aggregates gradients from all workers before sending updated model parameters.
A useful guideline suggests utilizing asynchronous training for smaller node counts, while synchronous training may be more effective for larger setups. For instance, Google researchers employed asynchronous parallelism for their 'flood-filling network' on 32 Nvidia K40 GPUs, whereas Argonne National Lab utilized synchronous parallelism for training the same model architecture on a supercomputer with 2048 compute nodes.
Pragmatically, one can also find beneficial compromises between the two training methods. Researchers from Microsoft have proposed a 'cruel' modification to synchronous training: allowing the slowest workers to fall behind, which they report can enhance training speed by up to 20% without sacrificing model accuracy.
Section 1.3: Centralized vs Decentralized Training
A central parameter server's limitation is that its communication demands grow linearly with the size of the cluster, creating a bottleneck that can inhibit scalability.
To circumvent this issue, multiple parameter servers can be deployed, with each responsible for a subset of the model parameters. In a fully decentralized framework, each compute node operates as both a worker and a parameter server for a portion of the model parameters. This decentralized structure equalizes the workload and communication demands across all machines, alleviating bottlenecks and enhancing scalability.
Section 1.4: Large-Batch Training
In data-parallelism, the global batch size increases in proportion to the size of the cluster. This scaling allows for the training of models with exceptionally large batch sizes that would be unattainable on a single machine due to memory constraints.
A critical aspect of large-batch training is determining the appropriate learning rate relative to the cluster size. For instance, if a model trains effectively on a single machine with a batch size of 32 and a learning rate of 0.01, what learning rate should be used when adding seven more machines, resulting in a global batch size of 256?
A 2017 study by Facebook researchers introduced the linear scaling rule, which simply scales the learning rate in proportion to the batch size (i.e., using 0.08 in this example). Using a GPU cluster with 256 machines and a global batch size of 8192 (32 per machine), the authors successfully trained a deep neural network on the ImageNet dataset in just 60 minutes—a remarkable achievement at the time, showcasing the potential of large-batch training.
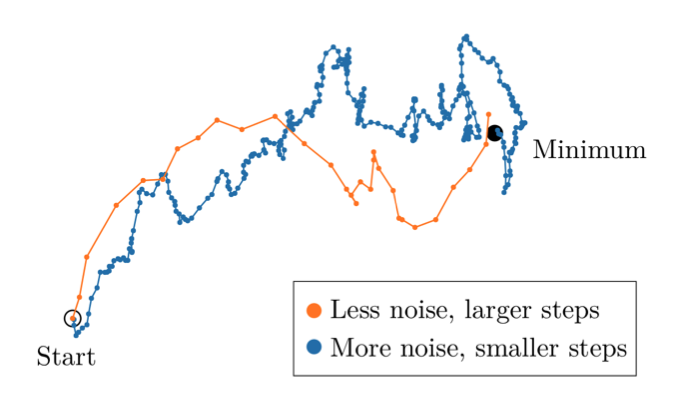
Visual representation of large-batch training. Larger batches yield less noisy gradients, enabling larger steps and consequently faster convergence.
However, there are limitations to large-batch training. To leverage larger batches effectively, the learning rate must be adjusted accordingly. If the learning rate is excessively high, the model may overshoot and fail to converge.
The constraints of large-batch training appear to vary by domain, with suitable batch sizes ranging from tens of thousands for ImageNet to millions for reinforcement learning agents engaged in games like Dota 2, as highlighted in a 2018 paper from OpenAI. Understanding the theoretical underpinnings of these limits remains an open research question, as much of ML research is empirical and lacks a solid theoretical foundation.
Chapter 2: Conclusion
In summary, distributed learning is an essential aspect of the ML framework for modern tech companies, allowing for the rapid training of larger models on extensive datasets. In data-parallelism, data is distributed, while in model-parallelism, the model itself is distributed. Both methods can be effectively combined.
Synchronous data-parallelism relies on workers sending gradients before the model updates, whereas asynchronous data-parallelism operates without waiting, leading to potential staleness. In a fully decentralized model, each worker also functions as a parameter server for a segment of the model parameters, equalizing computational and communication demands and alleviating bottlenecks.
Data-parallelism also facilitates large-batch training, where the learning rate is scaled linearly with the global batch size.
These concepts merely scratch the surface of distributed learning. This dynamic field is ripe with questions, such as the limits of large-batch training, optimization strategies for real-world clusters handling multiple workloads, managing diverse compute resources like CPUs and GPUs, and balancing exploration versus exploitation while navigating numerous models or hyperparameters.
Welcome to the captivating realm of distributed learning.
The second video, "A Primer on PAC-Bayesian Learning, and Application to Deep Neural Networks," discusses PAC-Bayesian learning principles and their applications in deep learning.