Data Preparation Techniques for Enhanced Analysis Efficiency
Written on
Chapter 1: Understanding Data Preprocessing
Data preprocessing encompasses a wide array of interconnected strategies and methodologies. In this section, we will explore some of the key concepts and techniques, highlighting their interconnections. The main topics we will cover include:
- Aggregation
- Sampling
- Dimensionality Reduction
- Feature Subset Selection
- Feature Creation
- Discretization and Binarization
- Variable Transformation
In general, these techniques can be categorized into two main groups: selecting data objects and attributes for analysis or altering attributes to enhance their utility. Both aim to optimize the data mining process in terms of time, expense, and quality. The following sections will provide more detailed insights.
Terminology Note
In the discussion that follows, we will occasionally use terms interchangeably, such as "feature" or "variable," to align with common practice.
Section 1.1: Aggregation
Aggregation is sometimes summarized by the phrase “less is more.” This process involves consolidating multiple objects into a singular entity. For instance, consider a dataset that records daily sales transactions from various store locations (e.g., Minneapolis, Chicago, Paris) over a year. An effective aggregation strategy for this dataset would involve replacing all individual transactions from a particular store with a single, comprehensive storewide transaction. This method significantly reduces the volume of data from potentially thousands of daily records to one for each store.
A key question arises: how is an aggregate transaction formulated? This involves combining the values of various attributes across all relevant records for a specific location. Quantitative attributes like price can be aggregated by computing sums or averages, while qualitative attributes (e.g., item types) may either be omitted or summarized into a comprehensive list of sold items.
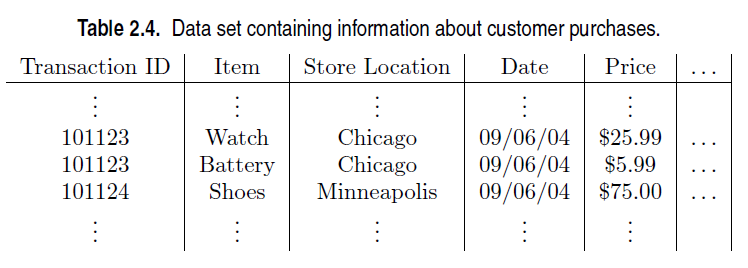
From a multidimensional perspective, aggregation can be viewed as the process of either eliminating certain attributes (like item type) or condensing the values of an attribute (e.g., summarizing days into months). This technique is prevalent in Online Analytical Processing (OLAP).
The advantages of aggregation are notable. Smaller datasets require less memory and processing resources, allowing for the application of more sophisticated data mining algorithms. Additionally, it offers a broader view of data, shifting from a detailed daily perspective to a monthly overview for each store. Moreover, the behavior of aggregated data tends to be more stable than that of individual data points. Statistically, aggregate measures, such as averages or totals, exhibit less variability compared to their individual components.
However, a downside to aggregation is the potential loss of significant details. For instance, aggregating monthly data might obscure which specific days experienced peak sales.
Section 1.2: Sampling
Sampling is a widely used strategy for selecting a subset of data objects for analysis. Historically, it has been employed in statistics for both preliminary data exploration and final analysis. In data mining, sampling serves a similar purpose but may have different motivations. While statisticians may sample due to the impracticality of collecting the entire dataset, data miners often opt for sampling to minimize the costs and time associated with processing all available data.
The essential principle of effective sampling is that a representative sample can yield results comparable to those obtained from the complete dataset. A sample is deemed representative if it mirrors the properties of the original data. For instance, if the average of the data is the focal point, a sample is representative if its average closely aligns with that of the entire dataset. However, the representativeness of a sample can vary, thus necessitating the selection of a sampling strategy that maximizes the likelihood of obtaining a representative sample.
Sampling Techniques
Numerous sampling methods exist; here, we will outline several fundamental techniques. The simplest is simple random sampling, where each item has an equal chance of being selected. There are two variations:
- Sampling without replacement: Once selected, an item is removed from the population.
- Sampling with replacement: An item can be selected multiple times since it remains in the population.
While these methods yield similar results for small sample sizes, sampling with replacement offers easier analysis due to the constant probability of selection.
In cases where the population contains various types of objects in unequal quantities, simple random sampling may fail to adequately represent less frequent types. This can pose challenges when comprehensive representation is required, such as when developing classification models for rare classes. In such scenarios, stratified sampling—which involves pre-defined groups—can be beneficial. For example, equal numbers of items may be drawn from each group, regardless of group size, or the number drawn may reflect the size of each group.

This challenge can be addressed through sampling. One effective method involves selecting a small data sample, calculating the pairwise similarities between data points, and clustering similar points. The final representative dataset is formed by choosing one point from each cluster. To ensure at least one point from each cluster is obtained, it is crucial to determine an adequate sample size. The relationship between sample size and cluster representation is illustrated in the following figure.
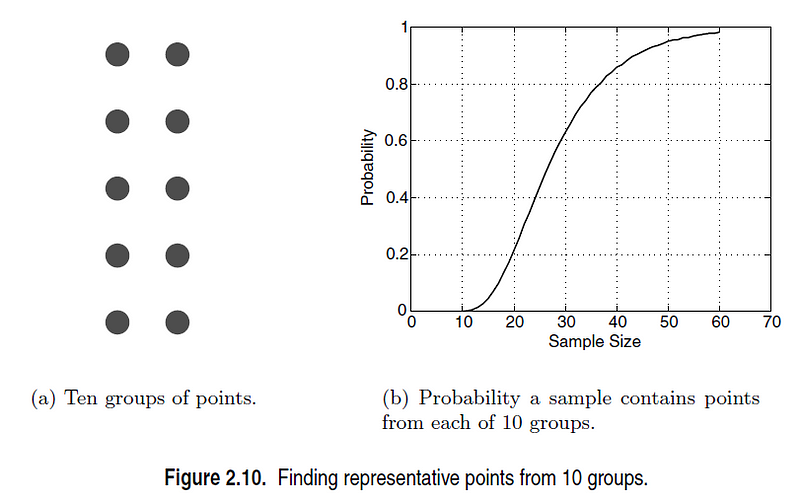
Chapter 2: Progressive Sampling
Determining the optimal sample size can be challenging. Consequently, adaptive or progressive sampling techniques are often employed. These approaches commence with a small sample and gradually increase the sample size until a satisfactory level is reached. While this method alleviates the initial burden of sample size determination, it necessitates a mechanism for evaluating the adequacy of the sample.
For instance, when using progressive sampling to develop a predictive model, accuracy generally improves with larger sample sizes. However, there comes a point where further increases in sample size yield diminishing returns in accuracy. The goal is to halt the sampling process once this plateau is reached. By monitoring accuracy improvements as sample sizes increase and conducting additional samples near the current size, we can estimate proximity to this leveling-off point, thus optimizing the sampling effort.
In the following video, "Pre-Modeling: Data Preprocessing and Feature Exploration in Python," you'll gain insights into effective data preprocessing techniques, including aggregation and sampling.
The video "Learn Data Science: Data Preprocessing in Python for Machine Learning" further elaborates on practical data preprocessing strategies essential for machine learning applications.